Details
If we want to improve the way documents are scored in Xapian during retrieval then we can directly do that by simply making changes to the weighting schemes in use in it. Xapian uses BM25Weight weighting scheme as default and provides a number of weighting schemes already such as BM25Weight, LMWeight, Tradweight, Boolweight and many others. These are defined in member functions of an abstract base class -- Xapian::Weight.
There is a common deficiency (i.e., lack of appropriate lower bound for TF normalization) in three state-of-the-art retrieval functions, Okapi BM25, PL2 and Dir that we need to remove in order to improve these functions. These functions represent the classical probabilistic retrieval model (Okapi BM25), the divergence from randomness approach (PL2), the language modeling approach (Dirichlet prior smoothing) and the vector space model (pivoted normalization).
In order to avoid overly penalizing very long documents, we need to lower-bound TF normalization to make sure that the “gap” of the within-document scores F(c(t,D),|D|,td(t)) between c(t, D)=0 and c(t, D) > 0 is sufficiently large where, F(·) is the within-document scoring function. However, we would not want that the addition of this new constraint changes the implementations of other retrieval heuristics in these state-of-the-art retrieval functions, because the existing retrieval heuristics in these retrieval functions have been shown to work fairly well.
Below are the improved weighting functions for BM25, PL2 & Dir, and a new normalization (Piv+) for existing vector space model.
1. BM25+ Weighting function
We have a lower-bounded BM25 function, namely BM25+, as shown in the following formula

where, δ is a pseudo TF value to control the scale of the TF lower bound and k1 is a parameter.
It was confirmed in these experiments that BM25+ works very well when we set δ = 1.
2. PL2+ Weighting function
A Lower-bounded PL2 function, namely PL2+, as shown in the following formula

3. Dir+ Weighting function
A Lower-bounded Dir function, namely Dir+, as shown in the following formula

where μ is the Dirichlet prior.
4. Piv+ Normalization function
A Lower-bounded pivoted normalization method (Piv+), as shown below

Other related notations are listed below:
- c(t, D) - Frequency of term t in document D
- c(t, Q) - Frequency of term t in query Q
- N - Total number of docs in the collection
- df(t) - Number of documents containing term t
- td(t) - Any measure of discrimination value of term t
- |D| - Length of document D
- avdl - Average document length
- c(t, C) - Frequency of term t in collection C
- p(t|C) - Probability of a term t given by the collection language model
5. Evaluation of weighting functions
The goal here is to see how well the new weighting functions can work in comparison to the existing functions.
Planning to use xapian-evaluation to evaluate and compare modified weighting functions with their counterparts to access their speed and retrieval effectiveness.
- BM25 vs BM25+
- PL2 vs PL2+
- Dir vs Dir+
Update: Using news collection dataset from FIRE for evaluation runs. This dataset contains sorted news articles/stories from two different news providers; BDNews24 and The Telegraph.
Project Timeline
I've created a separate page for project timeline on my project's main wiki page. You can click here to see project timeline.
Attachments (5)
-
BM25+.png
(10.5 KB
) - added by 10 years ago.
BM25+ weighting function
-
Dir+.png
(9.7 KB
) - added by 10 years ago.
Dir+ Weighting function
-
Piv+.2.png
(8.2 KB
) - added by 10 years ago.
Piv+ normalization function
-
Piv+.png
(8.2 KB
) - added by 10 years ago.
Piv+ normalization function
-
PL2+.png
(24.0 KB
) - added by 10 years ago.
PL2+ weighting function
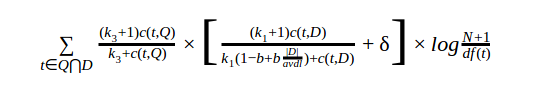{kind=link}
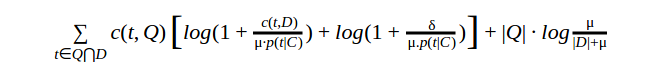{kind=link}
{kind=link}
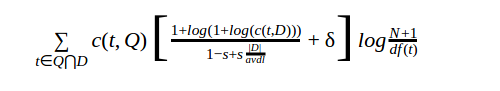{kind=link}
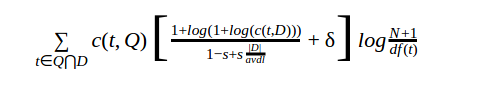{kind=link}
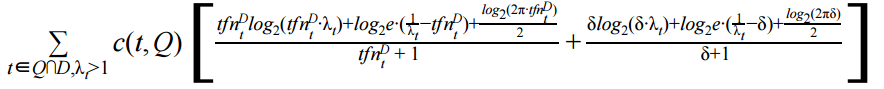{kind=link}
Download all attachments as: .zip