#756 closed enhancement (fixed)
Implement dice coefficient weight metric
| Reported by: | Guruprasad Hegde | Owned by: | Guruprasad Hegde |
|---|---|---|---|
| Priority: | normal | Milestone: | 2.0.0 |
| Component: | Library API | Version: | |
| Severity: | normal | Keywords: | |
| Cc: | Olly Betts, Gaurav Arora | Blocked By: | |
| Blocking: | Operating System: | All |
Description (last modified by )
In this task, I plan to implement dice coefficient(also known as dice similarity coefficient) metric. This metric is generally used to compare the similarity between two sets.
Please report if you find any mistake in explanation or have any concern related to the implementation.
Formula:

Q -> Query containing a set of terms C -> indexed candidate document
Statistics needed to compute the dcs(dice coefficient similarity for short) for each document in database:
- cardinality of the candidate document set.
- cardinality of the query set.
- the intersection of query set and candidate document set.
Example:
d1 = [one two three four five two four]
d2 = [one three four six eight three]
d3 = [nine ten three seven two]
Q1 = [one three]
Using dice coefficient formula, similarity metric for each document w.r.t given query Q1 is as below:
d1_score = 0.5714, d2_score = 0.5714, d3_score = 0.2857
Implementation plan:
In Xapian, Score computation is done over each term in the given query independently rather than over entire query set for a given document and score is accumulated over all the terms in a query.
The cardinality of query set and of a candidate document is constant over all the terms in a query. Hence denominator need to be computed only once for a selected document. Cardinality of document is nothing but number of unique terms(this stat is supported by Xapian::Weight class)
Intersection of query set and document set is number of terms from a query set appear in a given document. For each term in a query set, if term appears in a document, it contributes unit score(like boolean score).
Attachments (1)
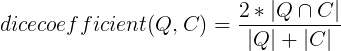{kind=link}
Change History (13)
by , 8 years ago
comment:1 by , 8 years ago
I'm not sure about your d1_score - I get:
- |Q₁ ∩ d₁| = 2
- |Q₁| = 2
- |d₁| = 5
So dicecoefficient(Q₁, d₁) = (2 * 2) / (2 + 5) = 4/7 (not 0.5)
Hence denominator need to be computed only once for a selected document
Theoretically, but actually you'll really need to compute it once per matching term for a selected document as the weight contributions come from separate Weight objects. You could invent some elaborate system for them to share the value rather than recompute it, but that's just going to end up being more costly than recomputing it - FP multiplication on modern hardware is fast.
comment:2 by , 8 years ago
So dicecoefficient(Q₁, d₁) = (2 * 2) / (2 + 5) = 4/7 (not 0.5)
Thanks, You are right, copy paste mistake.
You could invent some elaborate system for them to share the value rather than recompute it
Initially, I thought of using the scaling factor for this purpose. It doesn't seem right.
As you mentioned, computing the denominator every time seems the right way.
comment:3 by , 8 years ago
| Description: | modified (diff) |
|---|
comment:5 by , 8 years ago
There is a bug in upper_bound computation in the current implementation(https://github.com/xapian/xapian/pull/196/commits/66adf98348b0b4fd597796c0ee7034fe3038601a).
In upper bound computation, doc_length_lower bound() is used, but this should be size of unique term for document w.r.t doc_length_lower_bound. I couldn't figure out how to get that value. Any idea?
comment:6 by , 8 years ago
If I follow you want a lower bound on the number of unique terms in any document in the collection - we don't track that, but we know 1 is a lower bound for it (because documents without any terms wouldn't get weighted).
It's not necessarily a tight bound, but it's the best we can do right now.
We could certainly start to track bounds on the number of unique terms - you could usefully make that a stretch goal of your project (and for older databases without that information, we can return 1 for the lower bound and the doclength upper bound for the unique terms upper bound).
comment:7 by , 8 years ago
I updated the upper_bound computation as you suggested.
you could usefully make that a stretch goal of your project
Sure. I will keep this task in mind.
comment:8 by , 8 years ago
PR 196 merged to git master in 29776390aea1065e861525267392785e09036416.
I think that covers everything here, except the idea of tracking a bounds on the number of unique terms - is idea tracked somewhere else, or should we spin off a new ticket?
comment:9 by , 8 years ago
Thanks!
idea of tracking a bounds on the number of unique terms
It is not tracked anywhere except here. A new ticket will be good.
comment:10 by , 8 years ago
idea of tracking a bounds on the number of unique terms
This feature is tracked in #763
comment:11 by , 8 years ago
| Component: | Other → Library API |
|---|---|
| Milestone: | → 1.5.0 |
| Resolution: | → fixed |
| Status: | new → closed |
| Type: | task → enhancement |
Oops, failed to actually close this ticket.
dice_coefficient formula image