Table of Contents
Xapian Framework for Langauge Modelling
Xapian Frame Work is designed to handle Weighting scheme with there components as sum of individual terms contribution with an extra overall contribution. Whereas is based on product of the contribution of individual occurring probability.
Language Modelling will be applied to xapian framework with log trick.
By taking logarithm (which is a monotonic function, so the ordering is unaffected) then we can convert the product to a sum (since the logarithm of a product is the sum of the logarithms of the things being multiplied together)
Handel-ling Negative Values for log trick
- Since we take log of probabilities,Values generated are Negative and Negative Weights are Rejected by the xapian architecture.
- Linearly shift Negative Value to Positive.Multiplying with sufficiently large number to avoid sending negative value to architecture.
- Since value is Probability ,Divide by Document upper bound will be sufficient condition.But a much smaller number would be efficient,Hence statistically observe result for a sane default value.
Smoothing for Language Modelling
Smoothing the problem of adjusting maximum likelihood estimator to compensate for data sparseness.
General Format of Smoothing model is :
P(w,d) = { Ps(w|d ) if w is seen
{ alphad*p(w|C) otherwise

Various Smoothing techniques propose there version for Ps(Probability of seen) and alphad(document dependent/document independent)
Xapian will implement three basic smoothing function.

Basic Smoothing Techniques
1. Jelinek Mercer Smoothing
Involves Linear Interpolation of maximum likelihood model with the collection model using coefficient to control influence of each.
Since coefficient lamdad is constant and document independent,Hence the length normalization is constant.Jelinek Mercer smoothing accounts for explaining noisy and common words in query.
''lamda'' ---> small --> Less Smoothing {Relative Term weighting}
''lamda'' -> 0 ,Coordinate level Matching,Term independent,Rank simply by number of matched term.{'''Conjuctive interpolation of Query Term'''}
''lamda'' -> 1 ,Score will be dominated by terms with highest weight. {'''Disjunctive interpolation of Query Term'''}
Precision is more sensitive to Longer queries than the title query in test collection whereas for web collection both type of queries are sensitive.
Optimal value of lamda
Small Query - 0.1 {Conjuctive interpolation of Query Term}
Longer Query - 0.7 {Disjunctive interpolation of Query Term}
In our framework we are considering small query to be queries < 2 words.As average length of query for all major search engines is smaller than 3. reference
Small Query => query < 3 words
2. Dirichlet Priors Smoothing
alphad is document dependent for the Dirichlet priors.Hence smoothing will normalize score based on size of document.Since Longer document are more complete language model and require less adjustment hence Dirichlet smoothing apply less smoothing for larger documents.
parameter mue in Dirchlets smoothing also follow similar characteristics to Jelinek Mercer alphad.Smaller mue imples domination by count of matched terms and larger mue account for a more complicated behavious.
Optimal value for ume
mue -> 2000
3. Absolute Discounting
alphad is document sensitive for Absolute smoothing.Smoothing is larger for flatter distribution of words.More Smoothing for documents with relatively large coint of unique terms.
according to cunts of term in document absolute discounting ,make term weight flatter or skewed. Hence large smoothing will amplify weight diffrence for rare words and flatter for common words.
Precision for absolute discounting is sensitive for longer queries.
Optimal Value for delta
delta -> 0.7
Comparison of Smoothing Techniques based on Query Type
Title Query
Dirichlet Prior > Absolute Discounting > Jelinek Smoothing
Long Queries
Jelinek - Mercer smoothing > Absolute Discounting > Dirichlet Prior
Experiment shows Sensitivity of smoothing is more correlated with verbose query than longer queries.
Two Stage Smoothing
Two Different reasons for smoothing:
- To address small sample problem and explain unobserved words in document. {Estimation Role }
- Explain Common and Noisy words in query. {Query Modelling}
Dirichlet Prior Smoothing --> Better for Estimation role {Good performance on title queries} [[BR]] Jelinek-Mercer Smoothing --> Better for Query Modelling {Good performance on longer queries}
Xapian Default smoothing model
For a real time system we can combine both smoothing by applying Jelinek-Mercer followed by Dirichlet Prior smoothing.Jelinek-Mercer will first model the query and followed by Dirichlet Prior will account for missing and unseen terms.

Moreover combination of these two will be less sensitive to type and length of query.
Xapian will have all three smoothing with sensible default as two stage smoothing of Jelinek-Mrcer followed by Dirichlet smoothing.
Whereas user can select any of four smoothing techniques.
- Dirichlet Prior Smoothing
- Jelinek-Mercer Smoothing
- Absolute Discounting Smoothing
- Two Stage Smoothing
Bi-gram Implementation in Brass Back-end
Bi-gram are treated as just another term in the back-end.So indexer Concatenate the previous term and present term to form a bi-gram.This bi-gram is then added to back-end as just another term(Decided after discussion with Olly Betts).
Reason for Treating Bi-grams as just another term
- In most cases Architecture will treat bi-grams as just term i.e Opening PostingList for bi-gram term which will be similar to terms.
- In case we need list of just bi-grams.We can
if(term.find(" ") != string::npos)to find out bi-grams.Since this list is rarely accessed we it wont affect the performance.
- Since user don't know about how these are stored in back-end,so it wont also have benefit of better maintained back-end with bi-grams and uni-gram separate.(Which was also one of my thought in implementing not as term).
Per Document Statistics for Bigrams
But since storing them together affect the statistics of document length and moreover we will be required to have bi-gram document length for the !BigramLMWeight.So, these per document statistics are stored in postlist table as a posting entry with unique keys.
Currently following four per document statistics are stored in back-end.
Statistics String(send to make key) back-end key Document Length String("") string("\x00\xe0",2) Number Unique Terms String("nouniqterms") string("\x00\e8",2) Bigram Document Length String("bigramdoclen") string("\x00\xf0",2) Number Unique Bigrams String("nouniqbigrams") string("\x00\xf8",2)
Bug Fixing for Per Document Statistics
Regression test present in tests folder of xapian-core were ran.I got scared as suddenly all test were getting failed.Stating two types of error:
1. UnimplementedException: Number of unique terms not implemented for bigrams. 2. Invalid key writing in the post-list key
First Exception:
Problem causing first exception was pretty much clear as we didn't implemented the nouniqbigram function for chert.We need to find a way out from this problem by using try catch or check for back-end maybe.
Second Exception:
After a rigorous testing and investigation i found out,as i added new keys for per document statistics.while checking term name in the key i missed the cases for newly added keys.So for newly added keys it was getting failed.
Solving Document length in the TermList Table
I was trying to find out about why the document length was stored in both termlist table and postlist table.Now after current changes to brass Storing the 4 per document statistics. i was considering about should i store all the statistics in termlist or whether is make sense to remove the document length completely from the termlist table and access them from postlist table if required.Olly Suggested with a little idea to check whether it will be good idea to check what effect it have on time it takes for get_eset().
Following were the results:
Database Statistics:
UUID = c5db9f30-9b33-4ec1-85a8-544afe622040 number of documents = 913 average document length = 39.9354 document length lower bound = 8 document length upper bound = 6066 highest document id ever used = 913 has positional information = true
Time when document length taken from Termlist itself(when Document length is not removed from termlist table):
real 0m0.033s user 0m0.017s sys 0m0.013s
Timing when document length accessed from Postlist table:
real 0m0.103s user 0m0.060s sys 0m0.027s
Considering my database to be small,still there is some improvement in response time.So i would go with keeping document length in termlist table and checking terms to calculate bigram ,unigram lengths etc.
Best Practices Git Hub
Clone a repository.
git clone https://github.com/xapian/xapian.git
Creating and Working on Branch
Since it always better to keep you work feature wise and moreover able to merge the changes from the master once you think they are ready to go.Even if you work on forked copy its always better to work in branch and merge branch to the master when Done.
Creating Branch:
git branch branch_name
Checking out a branch(Going to a specific Branch):
git checkout branch_name
Getting changes from your master to the branch:
git merge master
Adding remote repo as main xapian repo and tracking upstream changes
Since you have forked a copy of code.But other are still working on the mainstream.Moreover in opensource you want to release your work and probably some time down the line it will be merged with main trunk.Hence its better to always get the upstream changes from main repo.So when you later on merge to trunk there and no conflict between your branch and master.So tracking upstream changes once a week is recommended.
Adding remote repo
$ git remote $ git remote add xapianmain https://github.com/xapian/xapian.git $ git remote -v
Tracking changes from remote repo
git pull xapianmain master
Small Commits
Since at anypoint of time you might want to discard any small part of implementation.hence its better to have small commits.Which helps in rolling back only part we dont want.Hence main key to work with git is have small commits.
References:
- Chengxiang Zhai and John Lafferty. 2004. A study of smoothing methods for language models applied to information retrieval. ACM Trans. Inf. Syst. 22, 2 (April 2004)
Attachments (5)
-
smoothingformula
(8.4 KB
) - added by 14 years ago.
Smoothing Formula
-
formulaalphad.jpeg
(8.3 KB
) - added by 14 years ago.
Alphad formula
-
smoothingformula.jpg
(14.1 KB
) - added by 14 years ago.
Table for formula of smoothing
-
smoothingformulatable.jpeg
(31.8 KB
) - added by 14 years ago.
Table for formula of smoothing
-
smoothingtwostage.jpg
(5.6 KB
) - added by 14 years ago.
two stage smoothing
{kind=link}
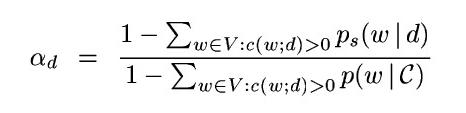{kind=link}
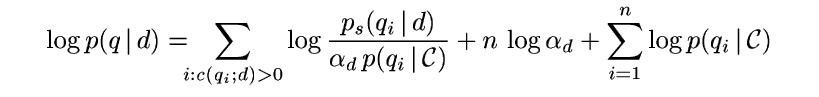{kind=link}
{kind=link}
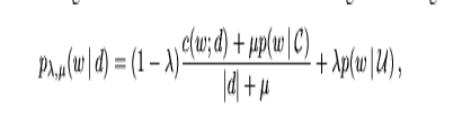{kind=link}
Download all attachments as: .zip